MapReduce is pivotal to big data as it has allowed the processing of massive datasets, which the earlier preferred format for data storage and analysis, RBDMS was not capable of doing.
In terms of big data analytics, the open-source framework of Hadoop has been a game changer. It has enabled storage of large datasets going up to petabytes in a cluster format, and faster processing of this distributed data. An essential feature of Hadoop is its ability for parallel processing which is executed via MapReduce.
MapReduce is defined as the distributed data processing and querying programming engine that effectively splits and spreads around the necessary computation activities on a dataset across a wide range of servers which are known as data clusters. A query that needs to run through a mega data set may take hours if situated in one computer server. This is however cut down to minutes when done in parallel over a spread of servers.
The term MapReduce refers to two critical tasks it handles on the Hadoop Distributed File System (HDFS) – the Map Job and the Reduce Job. The Map function takes the different input data elements available and processes them into an output data element, creating key value pairs. The Reduce function aggregates outputs created under the key value pairs, put them back together quickly and reliably in order to produce the required end-result.
Structurally, MapReduce has a single master Job Tracker and several slaves Task Tracker, one each per cluster. The master distributes and schedules the tasks to these slaves and keeps track of the assigned jobs, redoing any that fail. The slave tracker ensures that the assigned task is executed and communicates with the master
There are number of benefits of MapReduce that has made it an important element of Hadoop.
It allows developers to use any language like Java or C++ to write the applications, although Java is most preferred.
MapReduce can handle all forms of data whether structured or unstructured.
Another core feature of MapReduce is that it can easily run through petabytes of data stored in a data center due to its construct.
The MapReduce framework is also highly flexible in case of failures. If one dataset fails but is available in another machine, it can index and use the alternate location.
Today, there are several additional data processing engines like Pig or Hive that can be used to extract data from a Hadoop framework. These eliminate some of the complexity of MapReduce and make it easier to generate insights.
The time of coding data pipelines with high-level programming languages
ETL pipelines have been made with SQL since decades, and that worked very well (at least in most cases) for many well-known reasons.
In the era of Big Data, engineers and companies went crazy adopting new processing tools for writing their ETL/ELT pipelines such as Spark, Beam, Flink, etc. and started writing code instead of SQL procedures for extracting, loading and transforming their huge (or little — sic!) amount of data.
Since ETL/ELT pipelines can now be implemented as (a sequence of) jobs written in high-level programming languages like Scala, Java or Python, all your processing steps are expressed as pieces of code that can be structured, designed and, most of all, fully covered with automated tests in order to build robust development and deployment pipelines. In fact, data engineers can now take advantage of working in an environment that includes common tools like git, pull requests, automated tests, builds and even deployments saying goodbye to visual tools embedding huge SQL queries that are almost untestable, unreadable, unmaintainable and hated by any developer (people being involved in traditional DWH development can relate).
The most underrated benefit of this new way of doing ETL/ELT is that automated testing is now a real thing for data pipelines exactly as it is for any other piece of software around the world.
For the sake of clarity, let’s make an example with a piece of pseudo-code (similar to data processing frameworks like Apache Spark) representing a simple pipeline:
FooCollection inputRecords = // extract raw data from source
BarCollection enrichmentRecords = // extract data from external tableOutCollection outputRecords = inputRecords
.cleanAndNormalize
.enrichWithBar(enrichmentRecords)
.toBarCollectionoutputRecords.writeTo(destination)
Altough the pipeline is very simple, real jobs aren’t far away from this structure and one can immediately see that:
the code is easy to read and self-explanatory;
the code can be splitted in pieces that are easy to test and can be designed for being highly maintainable and well formatted using classes, methods, functions, interfaces and all the common structures an high-level programming language can offer;
pipelines can be implemented with TDD approach.
In brief, the whole project can be build around clean, tested and reusable code making your data pipelines robust, easy to maintain and deploy.
Dealing with the “full SQL” style
If you imagine to write the pipeline above with SQL, the result would be a very long query performing lots of case when statements, string manipulations, joins and type conversions all putted together in a single unmaintainable job.
Even when things and responsibilities would be wisely separated by splitting the job in multiple parts, still SQL wouldn’t benefit of having a robust automated testing framwork. Moreover, things like type safety, compile-time errors, coding best practices, test-driven approach and so on wouldn’t be possible at all.
Being honest, some commercial ETL and data integration tools offer some way to test your jobs (altough they are rarely used — but that’s another story). The problem is they are proprietary, sometimes not-free and limited solution that offer data and schema validation relying on pre-built operators and may vary a lot based on the tool of choice.
Intead, performing unit and integration testing with an high level language like Scala or Java is based on the same practices and rules as always and may vary very little from framework to framework with the advantage of giving you unparalleled robustness and coverage.
The Scary Effect of Managing Code
While developers and data engineers got exited with the new trend (since the beginnings of Hadoop-centered solution to newer cloud-based-and-serverless data platforms) many companies didn’t appreciated the amount of new technologies and code the new Big Data ecosystem brought in and started soon to suffer from (at least three) common problems:
lack of technical knowledge inside their BI teams;
shortage of skilled data engineers in the job market;
abundance of SQL-ninjas that were instantly made unable to write ETL/ELT pipelines for new big data projects.
Plus, since many Big Data technologies focused on providing “fast” SQL engines for querying and managing data stored on HDFS, filesystems and cloud blob storages, many companies started adopting tools like Hive, Drill, Impala, etc. not only for data exploration and analysis but as the core of their new ETL/ELT pipelines.
This architectural choice is mainly endorsed by companies who don’t have (and don’t want to hire) data engineers with the right skillset for dealing with these technologies or, instead of training their current employees, just prefer relying on their old-fashioned SQL experts for constructing and managing their brand new data lake.
Unfortunately, when I worked as consultant, I’ve seen more than one company implementing complex ETL/ELT pipelines with tools like Apache Hive embedding SQL queries within data integration tools offering classical GUIs with blocks-and-arrows and “big data connectors”. Under these circumstances, even a solid and rigorous data model didn’t prevent them of having an untested and unmaintainable system where every change is a painful development and is guaranteed to break something, somewhere (maybe in production).
These GUI-and-SQL with no-need-of-coding-skills solutions is a trend that will bring more harm than good.
I just covered the batch data processing use case, but with the need of implementing streaming solutions I feel these tools aren’t mature enough for solving newest challenges of data processing.
TL;DR: Is Big Data processing the end of SQL era?
Obviously not. SQL is a powerful tool for data analysis and exploration even in the Big Data ecosystem and it’s ok if your ETL/ELT jobs use pushdown for executing simple queries against a SQL-based engine when reading data. Moreover, there’s not a one-for-all solution: if all you have to do is (very) simple ETL and data integration, maybe you can still rely on some blocks executing dummy SQL queries onto your engine of choice.
However, when it comes to do complex data transformation and processing, it is a better option to use in-memory and distributed processing engines like Spark, Beam etc. writing your business logic in a high-level programming language within a rock-solid development ecosystem supported by the best practices of writing good code.
The result would be a robust, scalable and maintainable technology stack that both company and engineers would benefit from.
Not having the right technical skills should not be the reason for not using the right tools.
In this lesson, you will learn the basics of Hive and Impala, which are among the two components of the Hadoop ecosystem. We will compare Hive and Impala and learn how to execute queries using them.
Let’s look at the objectives of this Impala and Hive Tutorial.
After completing this lesson, you will be able to:
Explain Hive and Impala along with their needs and features
Compare Impala vs. Hive
Differentiate between relational database and Hive and Impala
Execute queries using Hive and Impala Needs and Features of Hive and Impala
In the next section of the Impala Hadoop tutorial, we will discuss the needs and features of Hive and Impala.
Introduction to Hive and Impala
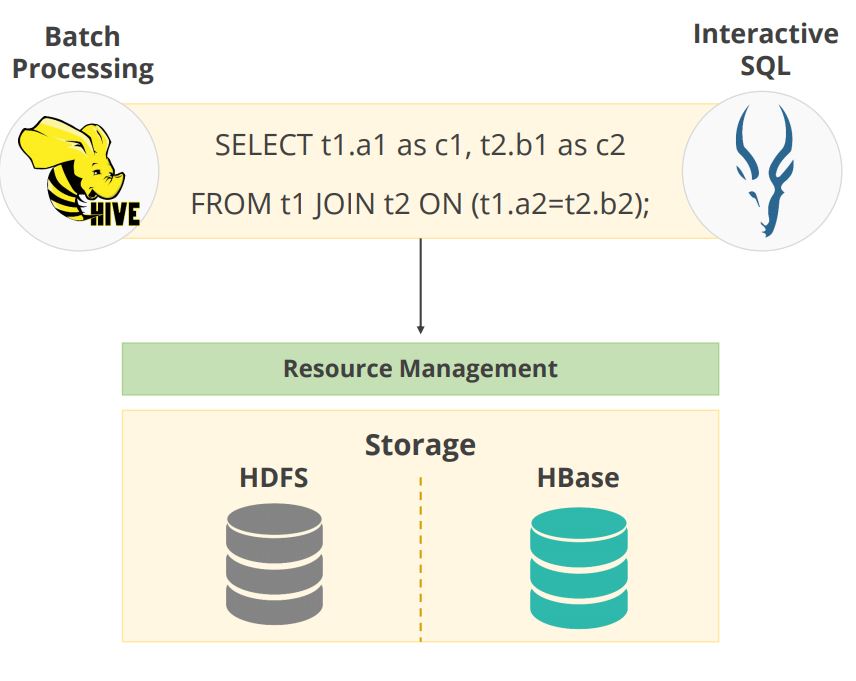
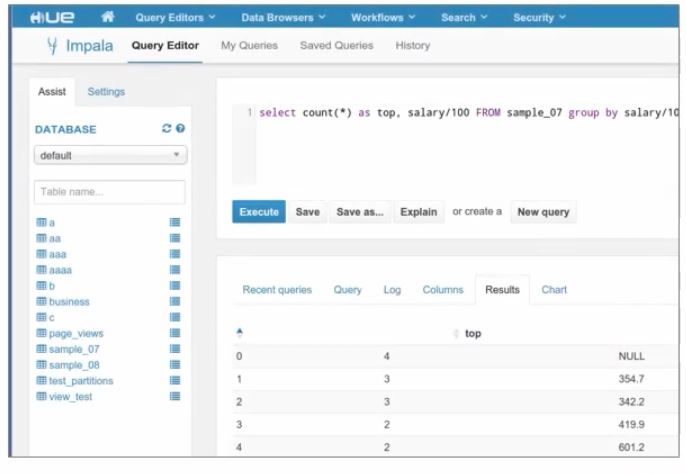
Hive and Impala are tools that provide a SQL-like interface for users to extract data from the Hadoop system. Since SQL knowledge is popular in the programming world, anyone familiar with it can use Hive and Impala.Broadly, the diagram shows how an SQL query in Hive and Impala is processed on the Hadoop cluster and can be stored or fetched from the storage components HDFS or HBase.
Let’s take a look at the similarities between the two Hadoop components in the next section of this Apache Impala tutorial.
Hive and Impala: Similarities
Hive, which helps in data analysis, is an abstraction layer on Hadoop. It is very similar to Impala; however, Hive is preferred for data processing and Extract Transform Load operations, also known as ETL.
Both Hive and Impala bring large-scale data analysis to a larger audience as users with no software development experience can easily adapt them. Users can leverage existing knowledge of SQL to work with Hive and Impala.
Writing a query in a map-reduce program is often complex and sometimes even requires 200 lines of Java code to complete the task of mapping and reducing. Whereas, writing queries in Hive and Impala is easy and can be done with a few lines of code.
Hive and Impala also offer interoperability with other systems. They are extensible through Java and external script. Many Business Intelligence tools support Hive and (or) Impala.
In the following section, we’ll discuss Impala vs. Hive.
Impala vs. Hive
Given below are some differences between hive and impala.
Impala
Impala was inspired by Google’s Dremel project and was developed by Cloudera around 2012.
It is an incubating Apache projectIt is designed for high concurrencies and ad hoc queries such as Business Intelligence and analytics
It has a high performance dedicated SQL engine
It uses Impala SQL for ad hoc queries and has a low query latency measured in milliseconds
Hive
Hive was developed by Facebook around 2007
It is an open source Apache project.
It has a high-level abstraction layer on top of MapReduce and Apache Spark.
It uses HiveQL to query the structured data in a metastore and generates MapReduce or Spark jobs that run on the Hadoop cluster
It is suitable for structured data such as periodic reviews and analysis of historic data
Which one to choose – Hive or Impala?
Hive has more features compared to Impala such as:
Use of non-scalar data types, extensibility mechanisms, sampling, and lateral views.
It is highly extensible and commonly used for batch processing.
Impala being a specialized SQL engine offering:
Five to fifty times faster performance compared to Hive:
It is ideal for interactive queries and data analysis.
Unlike Hive, Impala accommodates many concurrent users.
Over the last few years, features have been added to Impala. Although Hive is widely used, both the tools have their unique features.
Now, the following section of the Apache Hive tutorial, we will compare Relational Database Management Systems, or RDBMS, with Hive and Impala.
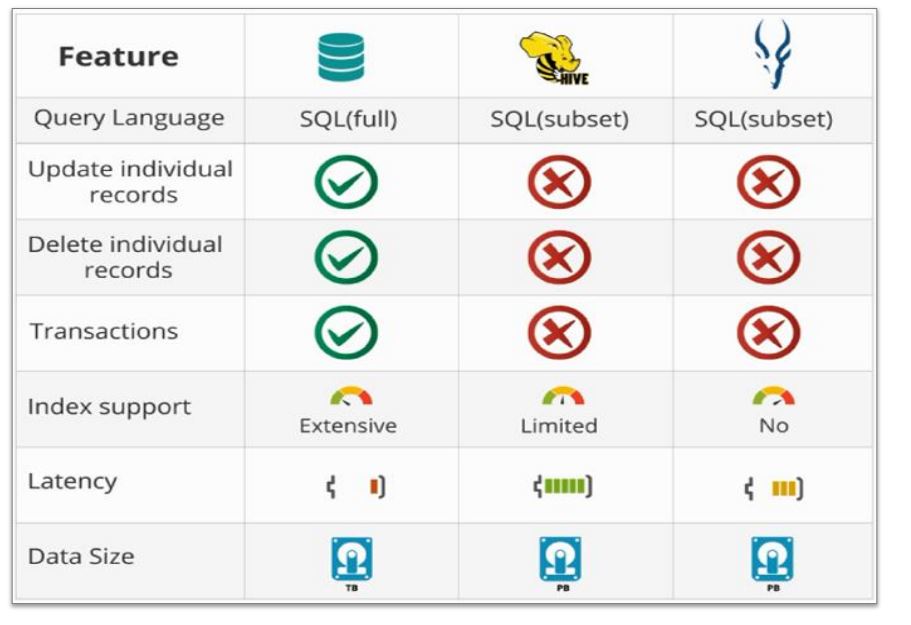
Relational Databases vs. Hive vs. Impala
The table given below distinguishes Relational Databases vs. Hive vs. Impala.
The few differences can be explained as given.
RDBMS has total SQL support, whereas Hive and Impala have limited SQL support.
You can update and delete individual records or rows from RDBMS, whereas these functionalities are not supported in Hive and Impala.
Transactions are possible only in RDBMS and not in Hive and Impala.
RDBMS has extensive index support, whereas Hive has limited index support and Impala has no index support.
The latency of SQL queries is very low in RDBMS, low in Impala, and high in Hive.
You can process terabytes of data in RDBMS, whereas you can process petabytes of data in Impala and Hive.
Interacting with Hive and Impala
Given below are the steps involved in executing a query on Hive and Impala. We will first discuss the steps in Hive.
Steps for executing a Query in Hive and Impala
Hive receives a SQL query and performs the following steps to get the result:
Parses HiveQL
Makes optimizations
Plans for execution
Submits job to the cluster
Monitors the progress
Processes the data: The job is sent to the data processing engine where it is either converted to MapReduce or processed by Spark.
Stores the data in HDFS
Let’s now discuss Impala
Impala performs the following steps after receiving a SQL query:
Parses Impala SQL
Makes optimizations
Plans for execution
Executes a query on the cluster
Stores data in a cluster
Note that Impala does not process the data using MapReduce or Spark, instead it executes the query on the cluster. This feature makes Impala faster than Hive.
Interfaces to Run Hive and Impala Queries
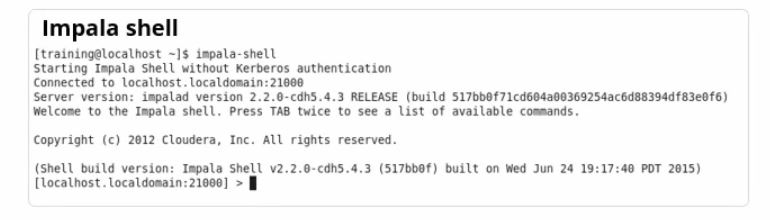
Hive and Impala offer many interfaces to run queries. The section displays the impala-shell.
The Command-line shell for Impala is impala-shell and for Hive is Beeline.
Similarly, in Hue Web UI you can access Hive through Hive Query Editor and Impala through Impala Query Editor as shown in the below section.
Accessing Hive through Impala Query Editor to access Impala can be shown in below image.
You can also connect Metastore Manager through the Open Database Connectivity/Java Database Connectivity driver, popularly known as ODBC/JDBC.
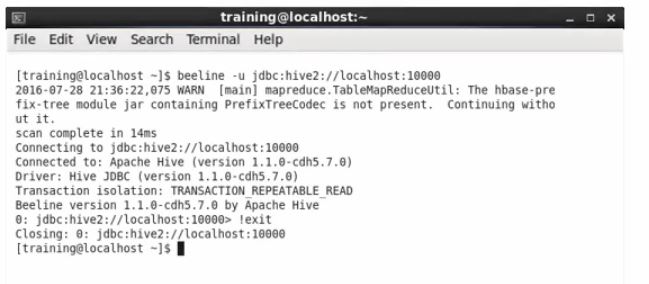
Running Hive Queries using Beeline
“!” Is used to execute Beeline commands. Here are a few commands to run Beeline:
!exit – to exit the shell
!help – to show the list of all commands
!verbose – to show added details of queries
You can view the section on the use of “!” to start Beeline.
Running Beeline from Command Line
You can execute the file using the “-u” option using the following command:
beeline –u …
-f simplilearn.hql
You can use HiveQL directly from the command line using the “-e” option using the following command:
beeline –u …
-e ‘SELECT * FROM users‘
You can use the command line shown in the section to continue running the script even after an error.
beeline –u …
-force=TRUE
You can execute any Hive SQL query from Hive terminal or Beeline. SQL command is terminated with a semicolon. You can run Impala from impala-shell and Hive from Beeline as displayed below.
Here we will learn iOS delegates in swift with examples and how to use iOS delegates in swift to communicate with multiple objects using Xcode editor with example.
To learn complete ios tutorials visit the following link:ios online course
iOS Delegates
IOS delegate is the same concept of all programming languages which means that delegate is used for communication between multiple objects. You can also imagine that ios delegate is the simple way to connect objects and communicate with each other. In another word, we also say that delegates are basically used to send messages from one object to another objects.
Now if you want to make your National identity card you enter the office and go to the counter 1 it takes the basic information and passed to the counter 3 for further process completion. Now the counter 3 is your delegate that handles the details which is passed by counter 1. Now after that counter 3 done the process and passed the information to counter 1 for further process.
Now we will see how to use iOS delegates in applications with an example using Xcode editor.
Create iOS Delegate App in Xcode
To create a new app in iOS Xcode open Xcode from /Applications folder directory. Once we open Xcode the welcome window will open like as shown below. In the welcome window click on the second option “Create a new Xcode Project” or choose File à New à Project.
Xcode application to create ios project
After selecting “Create a new Xcode project” a new window will open in that we need to choose template.
The new Xcode window will contain several built-in app templates to implement the common types of iOS apps like page-based apps, tab-based apps, games, table-view apps, etc. These templates are having pre-configured interface and source code files.
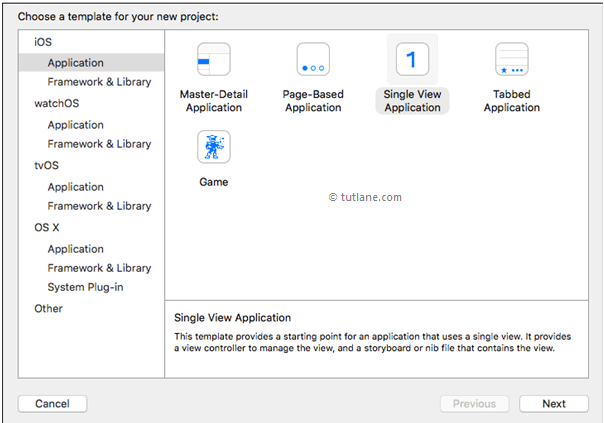
For this iOS hello world example, we will use the most basic template “Single View Application”. To select this one, Go to the iOS section in left side à select Application à In the main area of dialog select “Single View Application” and then click on the next button like as shown below.
Select single view application from ios xcode templates
After click Next we will get window like as shown below in this, we need to mention project name and other details for our application.
Product Name: “iOS Delegates”
The name whatever we enter in Product Name section will be used for the project and app.
Organization Name: “Tutlane”
You can enter the name of your organization or your own name or you can leave it as blank.
Organization Identifier: “com.developersociety”
Enter your organization identifier in case if you don't have any organization identifier enter com.example.
Bundle Identifier: This value will generate automatically based on the values we entered in the Product Name and Organization Identifier.
Language: “Swift”
Select language type as “Swift” because we are going to develop applications using swift.
Devices: “Universal”
Choose Devices options as Universal it means that one application is for all Apple devices in case if you have any specific requirement to run an app only for iPad then you can choose the iPad option to make your application restricted to run only on iPad devices.
Use Core Data: Unselected
This option is used for database operations. In case if you have any database related operations in your application select this option otherwise unselect the option.
Include Unit Tests: Unselected
In case if you need unit tests for your application then select this option otherwise unselect it.
Include UI Tests: Unselected
In case if you need UI tests for your application then select this option otherwise unselect it.
Once you finished entering all the options then click on Next button like as shown below
Enter Details to Create iOS Delegates Application in Xcode
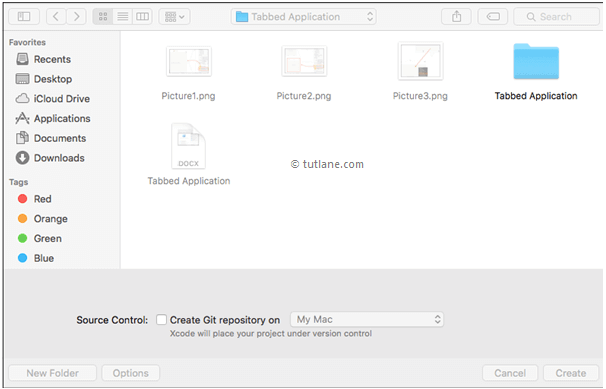
Once we click on the Next button new dialog will open in that we need to select the location to save our project. Once you select the location to save project then click on Create button like as shown below.
Give path to save new ios application in xcode
After clicking on the Create button, the Xcode will create and open a new project. In our project, Main.storyboard and ViewController.swift are the main files that we used to design app user interface and to maintain source code.
Main.storyboard – Its visual interface editor and we will use this file to design our app user interface
ViewController.swift – It contains the source code of our application and we use this file to write any code related to our app.
Now in project select Main.storyboard file, the Xcode will open visual interface editor like as shown below.
Now select ViewController.Swift file in your project that view will be like as shown below.
iOS Delegates Application View Controller Default Code in Xcode
Add iOS UI Controls to StoryBoard in Xcode
Now open Main.storyboard file and click in ViewController. Go to the Editor à Embed In à Navigation Controller like as shown below.
Add Navigation Controller to iOS Delegates Application
Now go to Object Library search for ViewController in Filter filed and drag the ViewController and drop into Main.storyboard like as shown below
Add viewcontroller to storyboard viewcontroller in ios delegates app
Same way drag the Bar Button Item from the object library and set the System Item “Add” when you select Add option the + button will appear like as shown below.
Add Bar Button Item to ViewController in iOS Swift Application
Now press Ctrl button in keyboard and drag “+” button and drop into third ViewController like as shown below
Add bar button to another viewcontroller in ios swift application
Once we make a connection between controllers our Main.storyboard file contains controllers relation like as shown below
ios delegates multiple controllers in storyboard file
Now we will add a new class file in our application for that Go to the File à New à File like as shown below.
Add New File in iOS Delegates Application
Now select “Cocoa Class” and click Next like as shown below
Add new cocoa class in ios delegates application in xcode
Once we click Next we will get new dialogue in that Give the name as “LastNameViewController” and select “UIViewController” option for Subclass of to extend functionality, select Language “Swift” and click on next button to create a new class like as shown below.
Give name to new class in ios delegates application in xcode
Now click on third ViewController and set the LastNameViewController class like as shown below
Map Controller to New Class in iOS delegates application
Now go to the Object library drag the button and one text field and drop into the third view Controller and change the button name like as shown below
Add ui controls button, label to view controller in ios delegates application
Connect iOS UI Controls to Code in Xcode
Now open the Editor in Assistant mode to make the connection between UI controls (textfield, button) and LastNameViewController.swift file for that click the Assistant button in the Xcode toolbar near the top right corner of Xcode to open the assistant editor like as shown below
Assistant Editor in iOS Xcode to Mapp Controls with Code
Now press Ctrl button in keyboard and drag the controls from your canvas to the code display in LastNameViewController.swift file like as shown below.
Map ios ui controls with viewcontroller.swift file in xcode editor
Once we map controls to LastNameViewController.swift file we need to write code to perform button action and our LastNameViewController.swift file should contain code like as shown below
// Do any additional setup after loading the view.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
Go to the Main.storyboard file clicks on Second View Controller drag the label from the object library and drop into the second ViewController then open the Editor in Assistant Mode and make the label connection to the ViewController.Swift file like as shown below
ios Add label control to viewcontroller and map control to code in xcode delegates application
Now click the connection between second ViewController and third ViewController and give the identifier name “Send” like as shown below.
Add connection between controllers in iOS delegates application
Once we finished all the required modifications our ViewController.swift file code will be like as shown below
let secondVC:LastNameViewController = segue.destinationViewController as! LastNameViewController
secondVC.delegate = self
}
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
Now we will run and see the output of the iOS Delegates application. To run application, first select required simulator (Here we selected iPhone 6s Plus) and click on Play button, located at the top-left corner of the Xcode toolbar like as shown below.
Run iOS Delegates Application By selecting simulator in Xcode
Output of iOS Delegates Application
Following is the result of the iOS Delegates application. Now run your application and click on + button icon when we click on “+” icon the third ViewController will open in that enter the name in a text field and click “ShowData” like as shown below
iOS Delegates Application Example Output or Result
Once the operation finished in the third viewcontroller then the data will send to the second viewcontroller using delegate like as shown below
Send to ViewController using Delegates in iOS Delegates Application
This is how we can use iOS delegates in our applications to send data from one controller to another controller based on our requirements.