





Welcome to lesson ‘Apache Flume and HBase’ of Big Data Hadoop tutorial which is a part of ‘big data training’ offered by OnlineItGuru. This lesson will focus on Apache Flume and HBase in the Hadoop ecosystem.
Let us look at the objectives of this lesson in the next section.
Objectives
After completing this lesson, you will be able to:
- Explain Apache Flume along with its uses
- Explain the extensibility and scalability features in Flume
- Identify Flume data sources and their flow
- Explain the components in the Flume architecture
- Explain the Flume Agent Configuration file with an example
- Define HBase along with its uses
- Explain the characteristics of HBase
- Analyze the HBase architecture and components
- Discuss HBase data storage and data models
- Differentiate between HBase and RDBMS
- Analyze the HBase Shell Commands
Let us first understand the Apache Flume, a Hadoop tool.
What is Flume in Hadoop?
Apache Flume is a distributed and reliable service for efficiently collecting, aggregating, and moving large amounts of streaming data from the web server into the Hadoop Distributed File System (HDFS).
It has a simple and flexible architecture based on streaming data flows, which is robust and fault-tolerant.
The diagram in the section depicts how the log data is collected from a web server by Apache Flume and is sent to HDFS using the source, channel, and sink components.

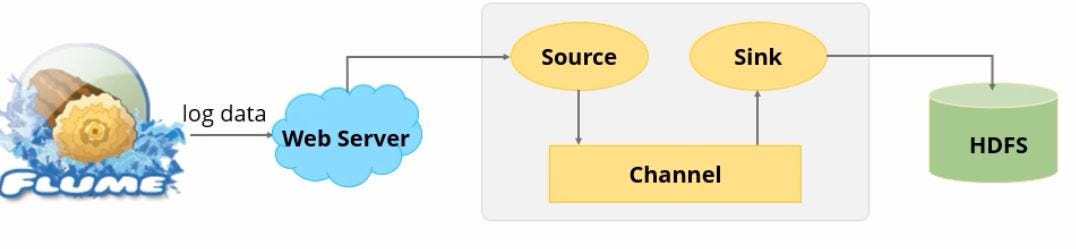
Let’s see how these components interact with each other.
- A Flume source consumes events delivered to it by an external source like a web server.
- When a Flume source receives an event, it stores it into one or more channels.
- The channel is a passive store that keeps the event until it’s consumed by a Flume sink. One example is the file channel, which is backed by the local file system.
- The sink removes the event from the channel and puts it into an external repository like HDFS or forwards it to the Flume source of the next Flume agent or next hop in the flow.
Let’s discuss why we need Flume with the help of a business scenario.
Why Flume?
Consider a scenario where a company has thousands of services running on different servers in a cluster that produces large log data. These logs should be analyzed together.
The current issue involves determining how to send the logs to a setup that has Hadoop. The channel or method used for sending them must be reliable, scalable, extensive, and manageable.
To solve this problem, Flume as a log aggregation tool can be used. Apache Sqoop and Flume are the tools used to gather data from different sources and load them into HDFS.
Sqoop in Hadoop is used to extract structured data from databases like Teradata, Oracle, and so on, whereas Flume in Hadoop sources data stored in different sources and also deals with unstructured data.
Let us now look at the flume model to collect and transfer data.
Flume Model
The Flume model comprises three Components:
- Agent
- Processor
- Collector
hese components are explained in the below diagram.
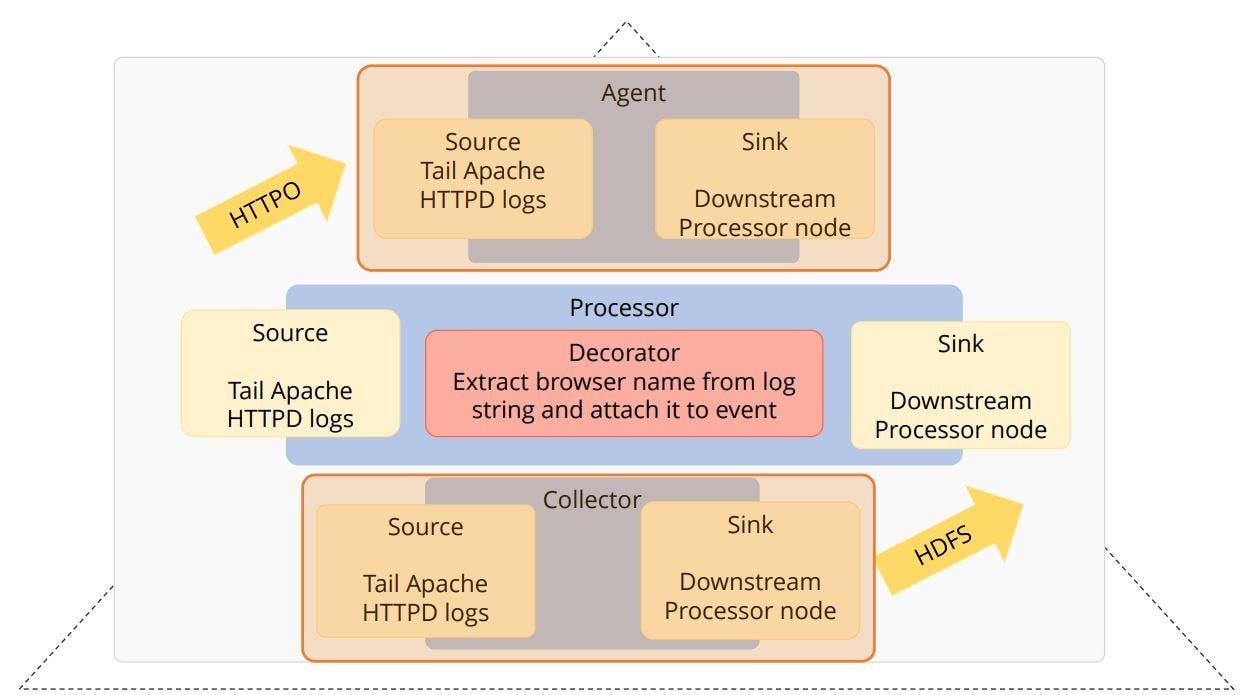
Agent: The agent is responsible for receiving data from an application. Running Flume agents ensures that data is continuously ingested into Hadoop.
Processor: The processor component is responsible for performing intermediate processing of jobs.
Collector: The collector component is responsible for writing data to the permanent HDFS storage.
Let us now understand what are the key goals of Flume.
Flume Goals
Flume works toward attaining certain key goals for data ingestion, which are:
- Ensuring reliability, using its tunable failure recovery modes
- Achieving extensibility by leveraging plug-in architecture for extending modules
- Achieving scalability by providing a horizontally scalable data path that can be used to form a topology of agents
- Achieving manageability by providing a centralized data flow management interface, hence making it convenient to manage across nodes
Let us now understand extensibility and scalability in Flume.
Extensibility in Flume
Extensibility is the ability to add new functionalities to a system. Flume can be extended by adding sources and sinks to existing storage layers or data platforms. Extensibility in flume is explained in below diagram.

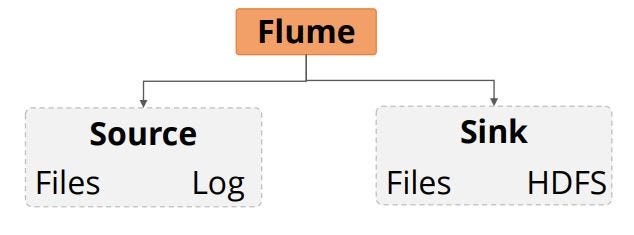
- General sources include data from files, syslog, and standard output from any Linux process.
- General sinks include files on the local file system or HDFS. Developers can write their own sources or sinks.
Scalability in Flume
Flume is scalable. It has a horizontally scalable data path, which helps in achieving load balance in case of a higher load in the production environment.
The image shown below depicts an example of horizontal scalability.
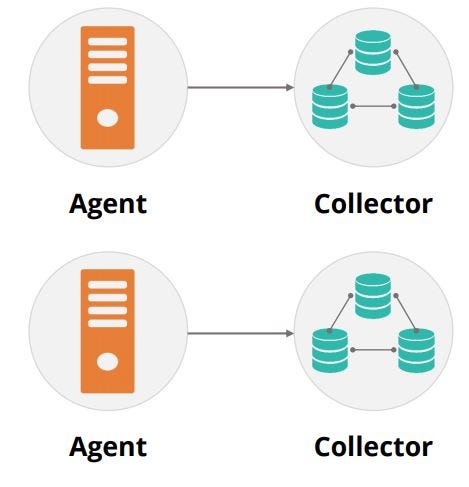
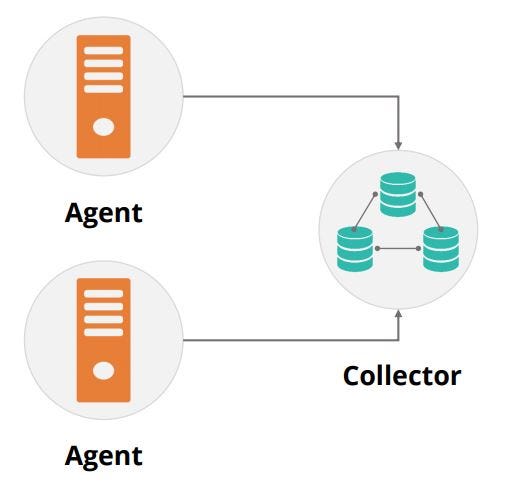
Assume there are two agents and two collectors. If one collector is down, then the two agents will scale down to just one collector as shown in the below diagram.
Let us now look into some common Flume data sources how flume data flow works to capture syslog data to hdfs.
Common Flume Data Sources
Some common Flume data sources are log files, sensor data, unit syslog, program output, status updates, network sockets, and social media posts.
Data can be streamed in the Hadoop cluster through these data sources. These Common Flume Data Sources are explained in the following diagram.
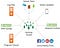
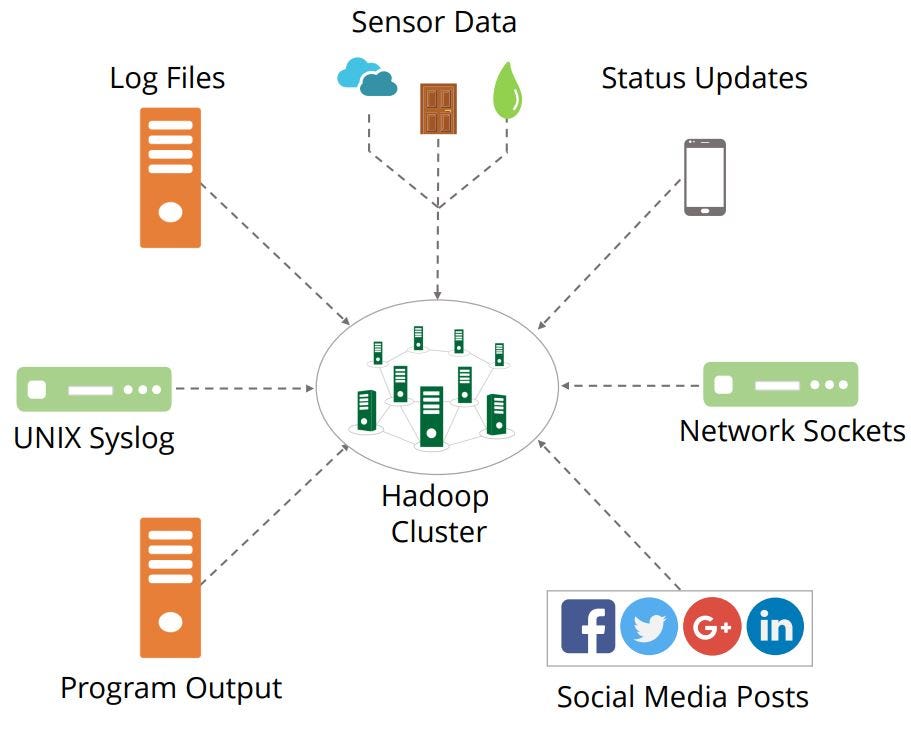
Flume Data Flow
The diagram illustrates how syslog data is captured to HDFS.

- The Message is logged on a server running a syslog daemon.
- Flume agent configured with syslog source receives the event.
- Source pushes an event to the channel, where it is buffered in memory.
- Sink pulls data from the channel and writes it to HDFS.
Let’s look at the components in the Flume architecture in the next section.
Components in Flume’s Architecture
Given below are the components in flume’s architecture.
Source: Receives events from the external actor that generates them
Sink: Sends an event to its destination, and stores the data in centralized stores like HDFS and HBase
Channel: Buffers events from the source until they are drained by the sink, and acts as a bridge between the sources and the sinks
Agent:Java process that configures and hosts the source, channel, and sink
Let’s learn more about each component in the subsequent sections.
Flume Source
The Flume sources are:
Netcat: Listens on a given port and turns each line of text into an event
Kafka:Receives events as messages from a Kafka topic
Syslog: Captures messages from UNIX syslog daemon over the network
Spooldir: Ingests data by placing files to be ingested into a “spooling” directory on disk
Flume Sink
The Flume sinks are:
Null: Discards all events it receives (Flume equivalent of /dev/null)
HDFS: Writes the event to a file in the specified directory in HDFS
HBaseSink: Stores the event in HBase
Flume channels
The Flume channels are:
Memory: Stores events in the machine’s RAM, and is extremely fast but not reliable as memory is volatile
File: Stores events on the machine’s local disk, and is slower than RAM but more reliable as data is written to disk
Java Database Connectivity or JDBC: Stores events in a database table. It is slower than file channel.
Let us discuss how to configure flume in the next section of this lesson.
Flume Agent Configuration File
All flume agents can be configured in a single Java file. In the case shown below, source, sink, and channel are defined as mysource, mysink, and, mychannel.

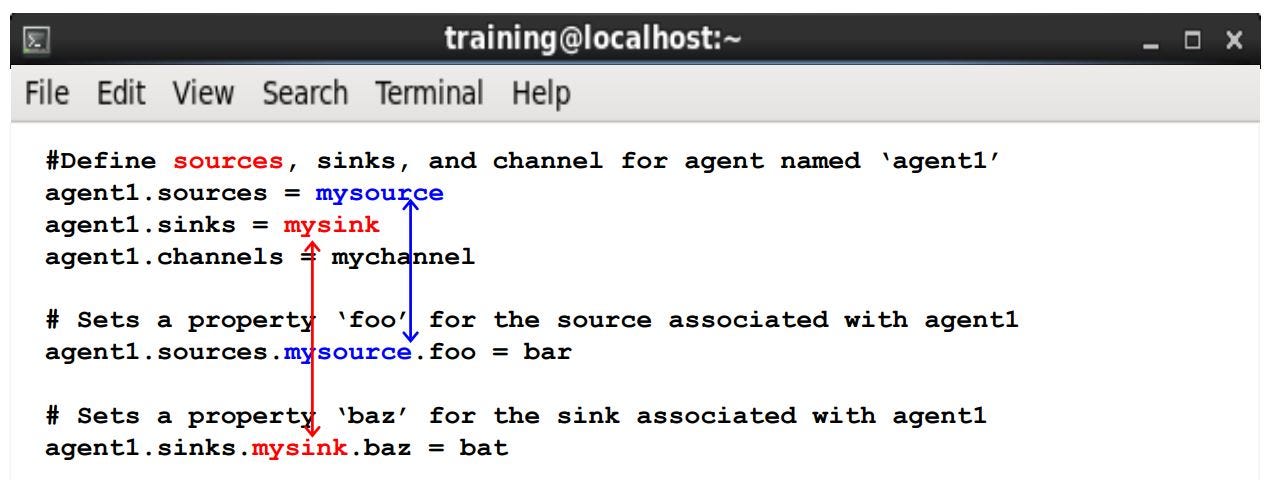
You can also set properties of the source and sink. You can see an example of how to configure flume components.
Example: Configuring Flume Components
The diagram below shows the process to configure a Flume Agent to collect data from remote spool directories and save to HDFS through the memory channel

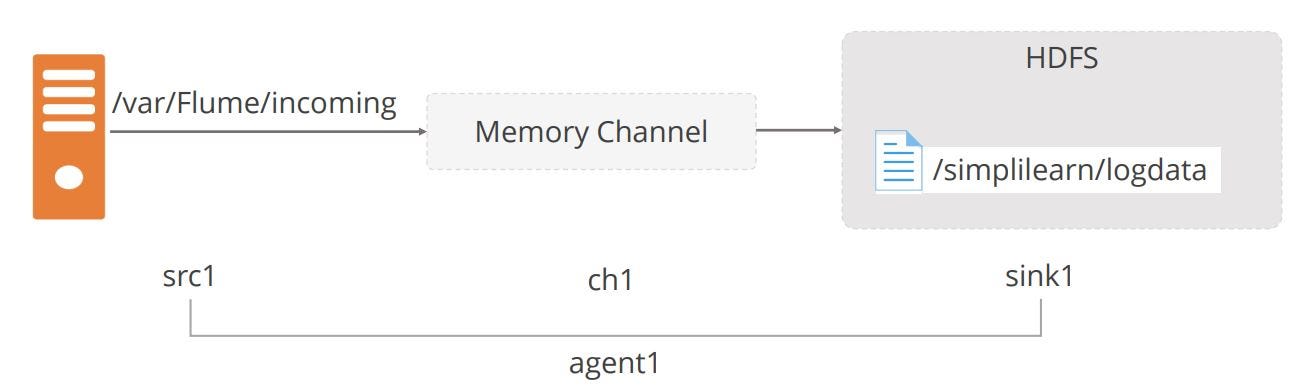
Here, we collect data from remote spool directories and save it to an HDFS-specified location through the memory channel.
As we have seen in the previous example, we define the source, sink, and channel as src1, sink1, and ch1, and later connect source and channel and then sink and channel. The following example explains how to Configure Flume Components.

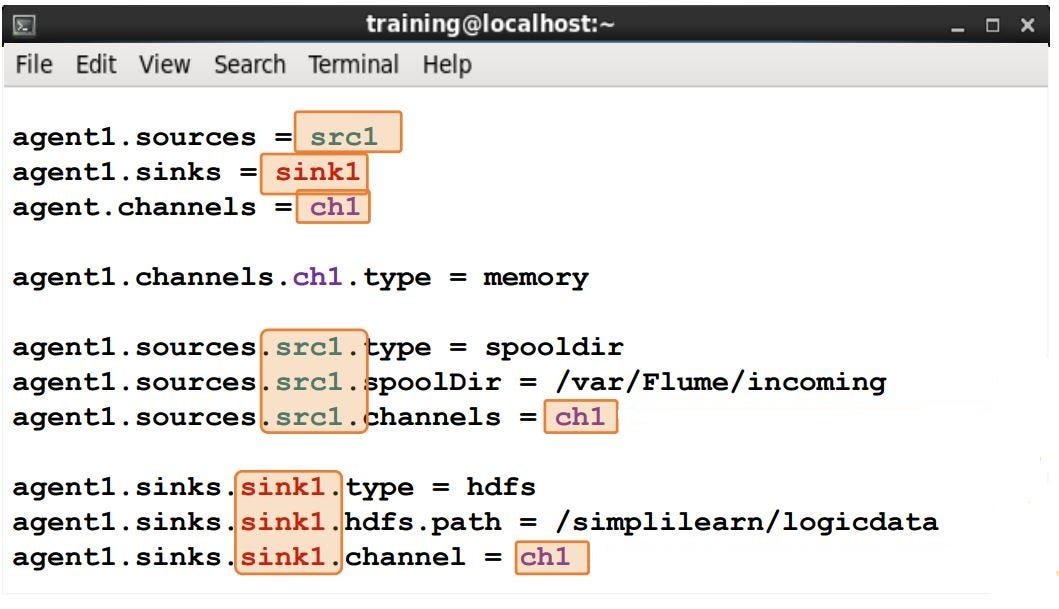
Flume Sample Use Cases
Flume can be used for a variety of use cases, such as:
- It can be used for collecting logs from Node in a Hadoop cluster.
- For collecting log from services such as httpd and mail and for process monitoring.
- Collecting impressions from a custom application for an advertising network like Meebo.
In the next section of this lesson, we will know about HBase which is the Hadoop component for storing data.
What is HBase?
HBase is a database management system designed in 2007 by Powerset, a Microsoft company. HBase rests on top of HDFS and enables real-time analysis of data.
HBase is modeled after Google’s Bigtable, which is a distributed storage system for structured data. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Some of the companies that use HBase as their core program are Facebook, Netflix, Yahoo, Adobe, and Twitter. The goal of HBase is to host large tables with billions of rows and millions of columns on top of clusters of commodity hardware.
Let us now discuss why Hbase is so important.
Why HBase?
- It can store huge amounts of data in a tabular format for extremely fast reads and writes.
- HBase is mostly used in a scenario that requires regular, consistent insertion and overwriting of data.
We know that HDFS stores, processes, and manages large amounts of data efficiently.
However, it performs only batch processing where the data is accessed in a sequential manner. This means one has to search the entire dataset for even the simplest of jobs. Hence, a solution was required to access, read, or write data any time regardless of its sequence in the clusters of data.
HBase Real Life Connect — Example
You may be aware that Facebook has introduced a new Social Inbox integrating email, IM, SMS, text messages, and on-site Facebook messages. They need to store over 135 billion messages a month.
Facebook chose HBase because it needed a system that could handle two types of data patterns:
- An ever-growing dataset that is rarely accessed
- An ever-growing dataset that is highly volatile You read what’s in your Inbox, and then you rarely look at it again.
Characteristics of HBase
HBase is a type of NoSQL database and is classified as a key-value store. Some characteristics of HBase are:
- Value is identified with a key.
- Both key and values are Byte Array, which means binary formats can be stored easily.
- Values are stored in key-orders.
- Values can be quickly accessed by their keys
HBase is a database in which tables have no schema; column families and not columns are defined at the time of table creation.
HBase Architecture
HBase has two types of Nodes: Master and RegionServer.
Master Node
There is only one Master node running at a time, whereas there can be one or more RegionServers. The high availability of the Master node is maintained by ZooKeeper, a service for distributed systems.
The Master node manages cluster operations like an assignment, load balancing, and splitting. It is not a part of the read or writes path.
RegionServer Node
The RegionServer host’s tables perform reads, and buffers write. Clients communicate with the RegionServer to read and write. A region in HBase is the subset of a table’s rows.
The Master node detects the status of RegionServers and assigns regions to RegionServers.
Let us now look at the HBase Components.
HBase Components
The image represents the HBase components which include HBase Master and multiple RegionServers.

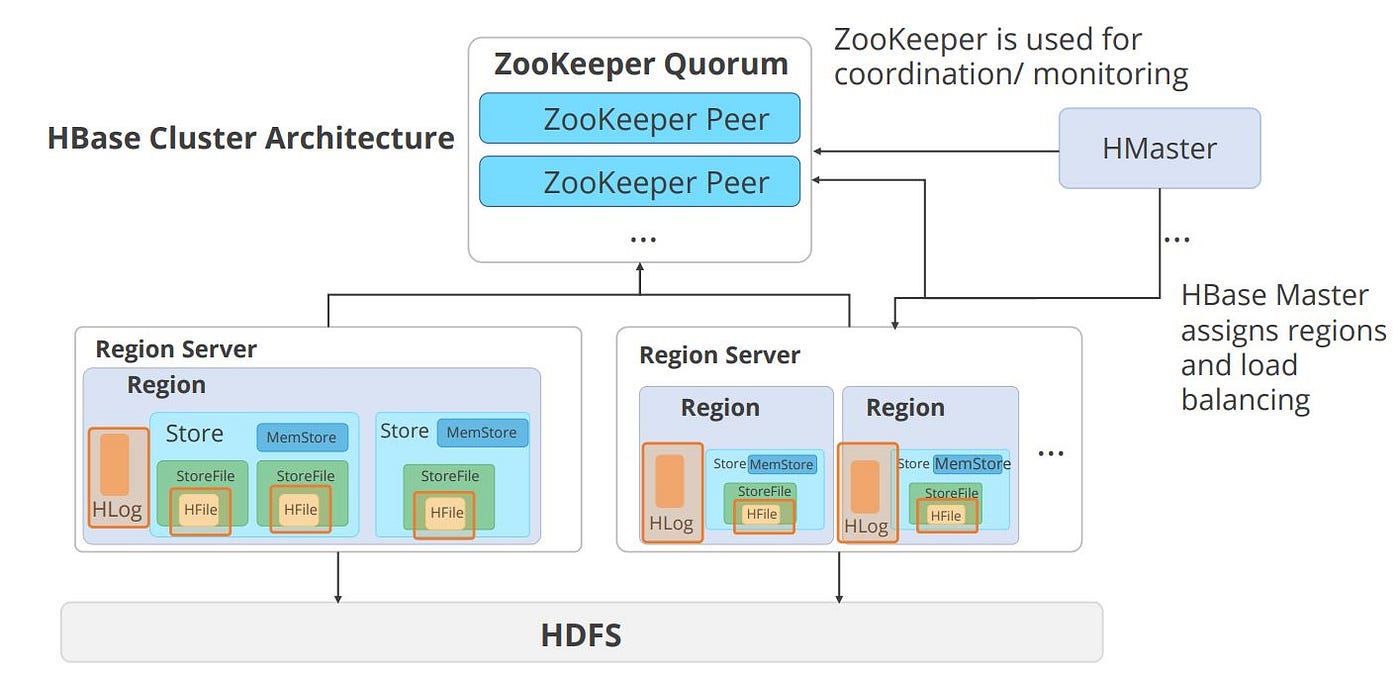
- The HBase Master is responsible for the management of the schema stored in HDFS.
- RegionServers act like availability servers that enable the maintenance of a part of the complete data stored in HDFS based on the requirement of the user.
- The RegionServers perform this task by using the HFile and Write Ahead Log, or WAL, service.
- The RegionServers always stay in sync with the HBase Master. It is the ZooKeeper that makes the RegionServers perform stable sync with the HBase Master.
Storage Model of HBase
The two major components of the storage model are Partitioning and Persistence and data availability.
Partitioning
Partitioning is one part of the storage models of HBase, where a table is horizontally partitioned into regions. Each region is composed of a sequential range of keys and is managed by a RegionServer. A RegionServer may hold multiple regions.
Persistence and data availability
Persistence and data availability are also important components of the storage model. HBase stores its data in HDFS does not replicate RegionServers and relies on HDFS replication for data availability.
The region data is first cached in memory. Updates and reads are served from the in-memory cache called MemStore. Periodically, MemStore is flushed to HDFS. WAL stored in HDFS is used for the durability of updates.
Row Distribution of Data between Region Servers
The image describes the distribution of rows in structured data using HBase.

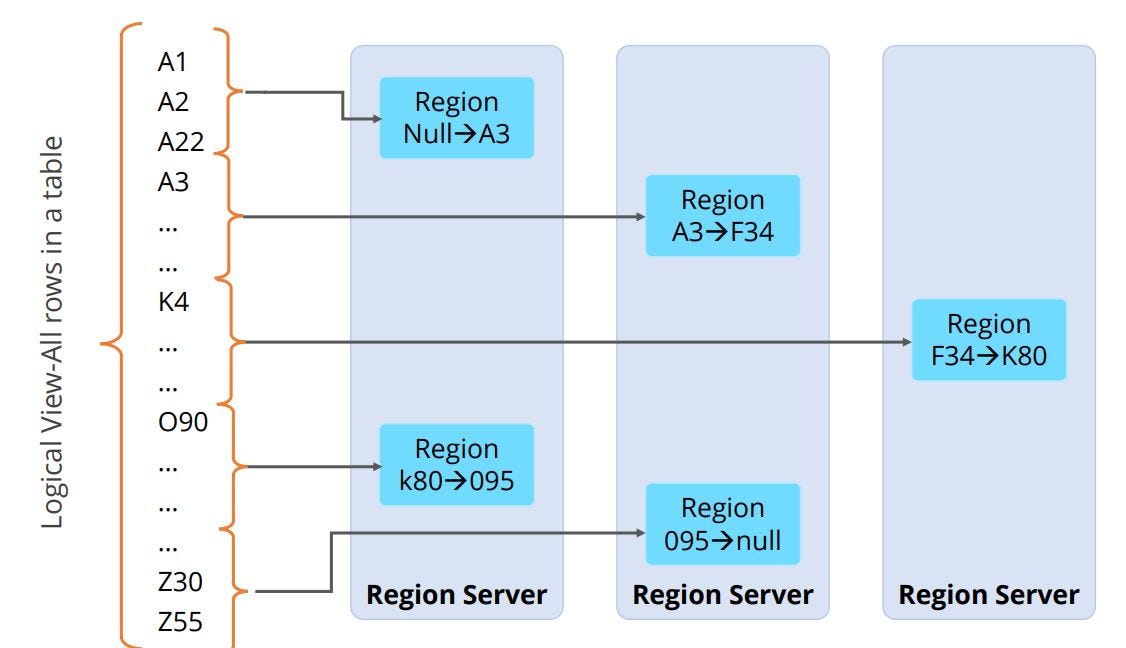
It shows how the data is sliced and maintained in individual RegionServers, depending on the requirement of the user. This type of distribution ensures availability of data for a specific user.
Data Storage in HBase
Data is stored in files called HFiles or StoreFiles that are usually saved in HDFS.
An HFile is a key-value map generated due to the MapReduce operations performed by Hadoop.
When data is added, it is written to WAL and stored in memory. This in-memory data store is called MemStore. HFiles are immutable since HDFS does not support updates to an existing file.
To control the number of HFiles and keep the cluster well-balanced, HBase periodically performs data compactions.
Let us look at the Data Model in the next section.
Data Model
The data model in HBase is as shown below.

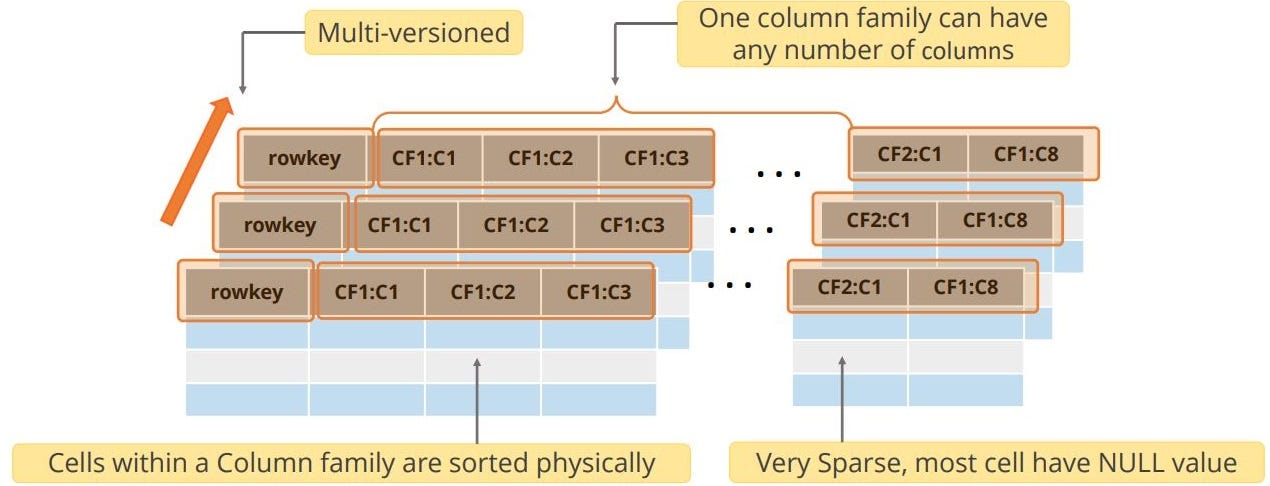
Features of the data model in HBase are explained in the following diagram:

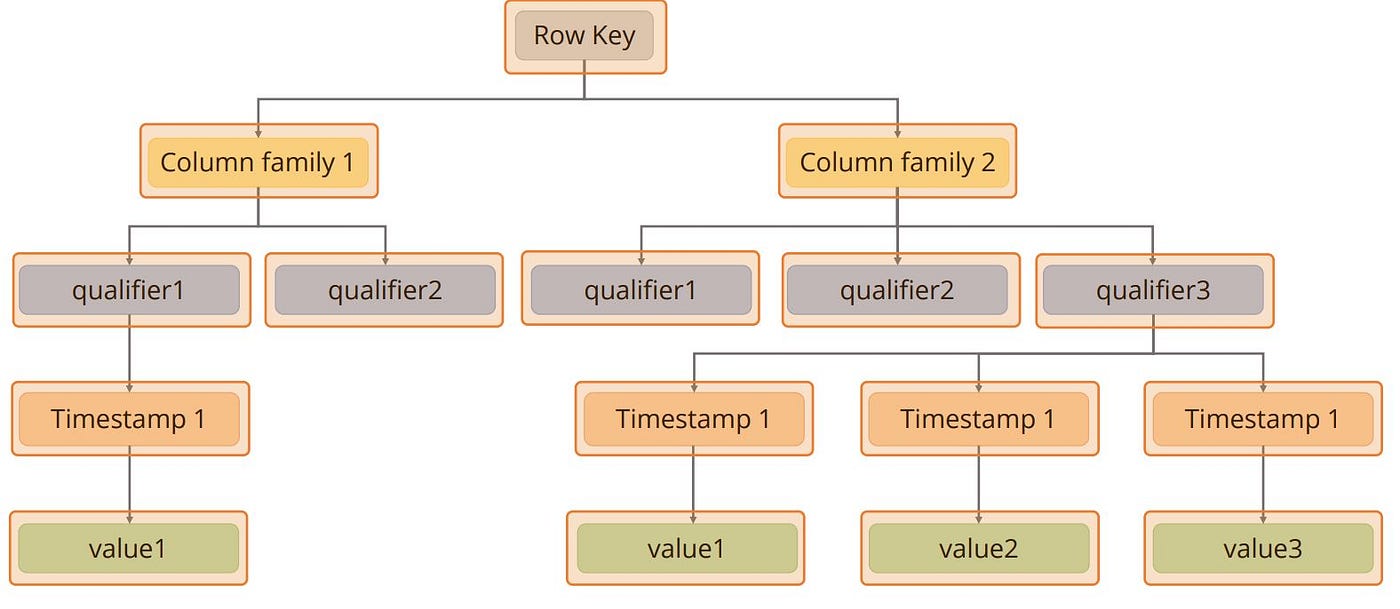
In HBase, all tables are sorted by row keys. At the time of table creation, you need to define its column families only. Each family may consist of any number of columns, and each column consists of any number of versions.
Columns exist only when inserted; however, NULLs are free. Columns within a family are sorted and stored together. Everything, except table names, is stored as a ByteArray.
A row key, a column family with columns, and a timestamp with version identify a row value. The data model has many other features.
The first identifier of the data model is a row key. Column families are associated with column qualifiers. Each row has a timestamp and an associated value.
Lets now understand when we can use HBase.
When to use HBase?
- HBase is used when you have enough data in millions or billions of rows.
- It can be used when you have sufficient commodity hardware with at least five nodes.
- It is the developer’s responsibility to evaluate HBase carefully for mixed workloads.
- Developers can use HBase for random selects and range scans by key.
- They can also utilize HBase in the variable schema.
Let us now understand how HBase differs from a Relational Database Management System (RDBMS).
HBase vs. RDBMS
The table shows a comparison between HBase and a Relational Database Management System (RDBMS):
HBase
RDBMS
Automatic partitioning
Usually manual, admin-driven partitions
Scales linearly and automatically with new nodes
Usually scale vertically by adding more hardware resources
Uses commodity hardware
Relies on expensive servers
Has fault tolerance
Fault tolerance may or may not be present
Leverages batch processing with MapReduce distributed processing
Relies on multiple threads or processes rather than MapReduce distributed processing
Connecting to HBase
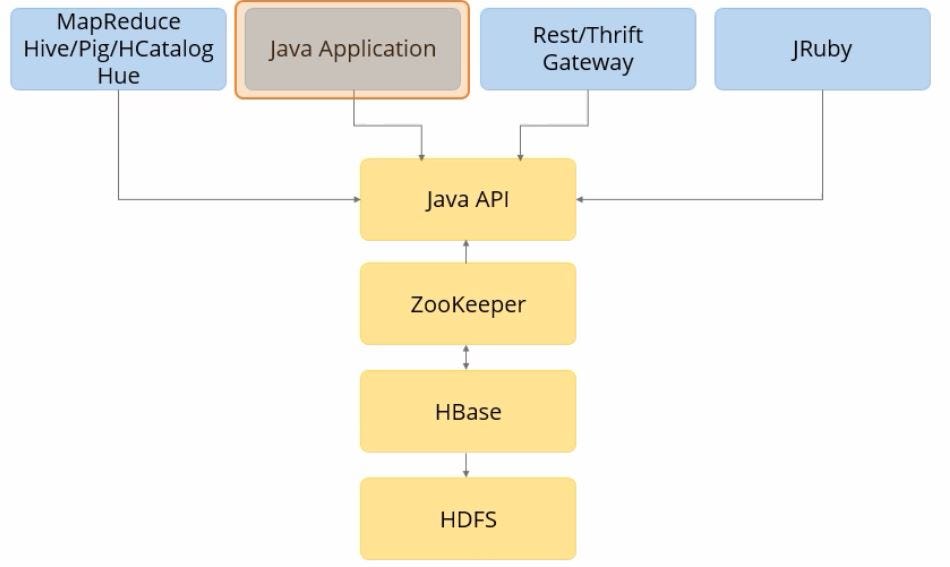
You can connect to HBase using any of the following media:
- Java Application Programming Interface or API: It can be used to conduct usual operations such as get, scan, put, and delete
- Thrift or REST services: They can be used by non-Java clients
- JRuby: It is a built-in convenient shell for performing the majority of operations, including admin functions, from the command line
- Hive, Pig, HCatalog, or Hue
The Image below explains media’s to connect to HBase.

Let us now look at the HBase Shell Commands.
HBase Shell Commands
Some of the commands that can be used from the HBase shell include:
- Create for the creation of a table:
hbase> create ‘t1′, {NAME => ‘f1′}, {NAME => ‘f2′}, {NAME => ‘f3′}
hbase> #
The above in shorthand would be the following:
hbase> create ‘t1′, ‘f1′, ‘f2′, ‘f3′
- Describe for describing the named table:
hbase> describe ‘t1′
- Disable for disabling the table:
hbase> disable ‘t1′
- Drop for dropping the table:
hbase> drop ‘t1′
- List for listing the tables:
hbase> list
Other commands that can be used from the HBase shell are:
- Count for counting the number of rows in a table:
hbase> count ‘t1′
hbase> count ‘t1′, INTERVAL => 100000
- Delete for deleting a cell value:
hbase> delete ‘t1′, ‘r1′, ‘c1′, ts1
- Get for getting the contents of a row or cell:
hbase> delete ‘t1′, ‘r1′
hbase> delete ‘t1′, ‘r1′, {COLUMN => ‘c1’,
TIMERANGE => [ts1, ts2], VERSIONS => 4}
- Put for putting a cell value:
hbase> put ‘t1′, ‘r1′, ‘c1′, ‘value’, ts1
- Scan for scanning a table’s values:
hbase> delete ‘t1′, ‘r1′, {COLUMN => [‘c1’, ‘c2’], LIMIT => 10, STARTROW => ‘xyz’}
Summary
Let us now summarize what we have learned in this lesson.
- Apache Flume is a distributed and reliable service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System, or HDFS.
- Flume has a horizontally scalable data path which helps in achieving load balance in case of the higher load in the production environment.
- Few common flume data sources are log files, sensor data, unit Syslog, program output, status updates, network sockets, and social media posts.
- HBase is mostly used in a scenario that requires regular, consistent insertion and overwriting of data.
- HBase is a type of NoSQL database and is classified as a key-value store. HBase has two types of Nodes‚ Master and RegionServerPlanning
Conclusion
This concludes the lesson on Apache Flume and HBase.


0 Comments:
Post a Comment