





In this data-driven era, there is no piece of information that can’t be useful. Every bit of data stored on the systems of your company, no matter its field of activity, is valuable. Maximizing the exploitation of this new black gold is the fastest way towards success, because data offers an enormous amount of answers, even to questions you still haven’t thought of yet.
Luckily for us, setting up a Big Data pipeline that can efficiently scale with the size of your data is no longer a challenge since the main technologies within the Big Data ecosystem are all open-source.
No matter which technology you use to store data, whether it’s a powerful Hadoop cluster or a trusted RDBMS (Relational Database Management System), connecting it to a fully-functioning pipeline is a project that’ll reward you with invaluable insights. One pipeline that can be easily integrated within a vast range of data architectures is composed of the following three technologies: Apache Airflow, Apache Spark, and Apache Zeppelin.
To learn Big data and Hadoop:big data online training
First, let Airflow organize things for you
Apache airflow is one of those rare technologies that are easy to put in place yet offer extensive capabilities. The workflow management system that was first introduced by Airbnb back in 2015 has gained a lot of popularity thanks to its powerful user interface and its effectiveness through the use of Python.
Airflow relies on four core elements that allow it to simplify any given pipeline:
- DAGs (Directed Acyclic Graphs): Airflow uses this concept to structure batch jobs in an extremely efficient way, with DAGs you have a big number of possibilities to structure your pipeline in the most suitable way
- Tasks: this is where all the fun happens; Airflow’s DAGs are divided into tasks, and all of the work happens through the code you write in these tasks (and yes, you can literally do anything within an Airflow task)
- Scheduler: unlike other workflow management tools within the Big Data universe (notably Luigi), Airflow has its own scheduler which makes setting up the pipeline even easier
- X-COM: in a wide array of business cases, the nature of your pipeline may require that you pass information between the multiple tasks. With Airflow that can be easily done through the use of X-COM functions that rely on Airflow’s own database to store data you need to pass from one task to another
Having an Airflow server and scheduler up and running is a few commands away and in a few minutes you could find yourself navigating the friendly user interface of your own Airflow web-server, which is quite easy to master:
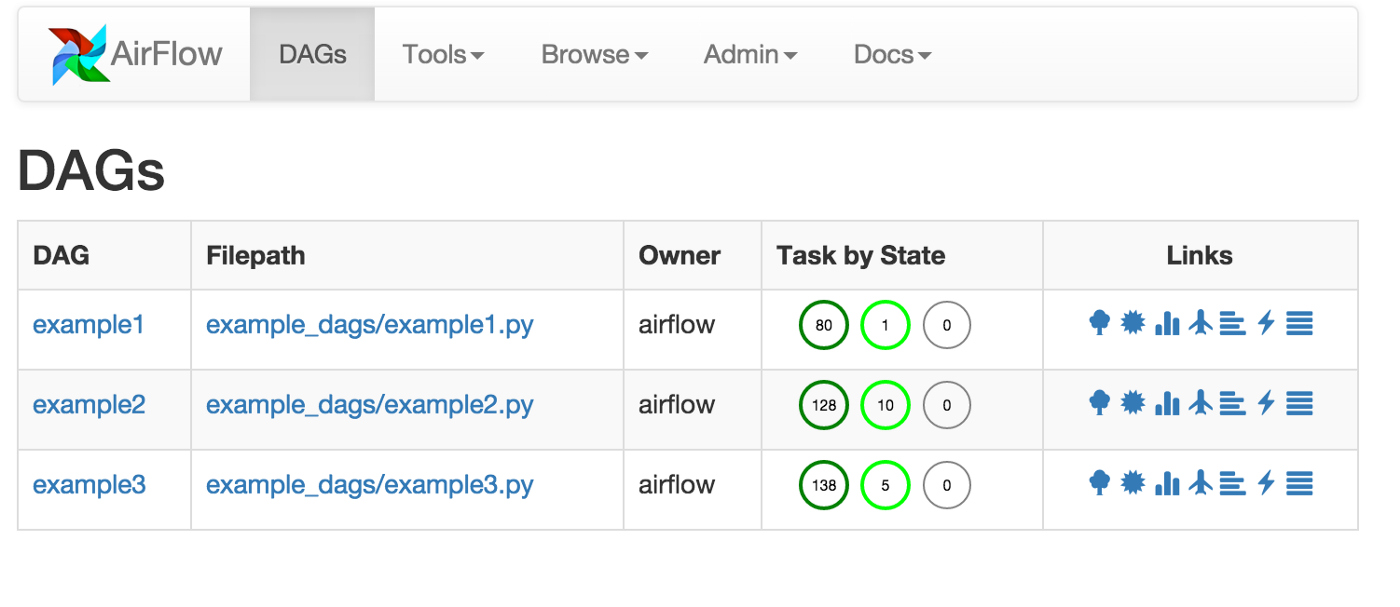
The next step consists of connecting Airflow to your database / data management system, fortunately Airflow offers a pretty straightforward way to do that through the UI:
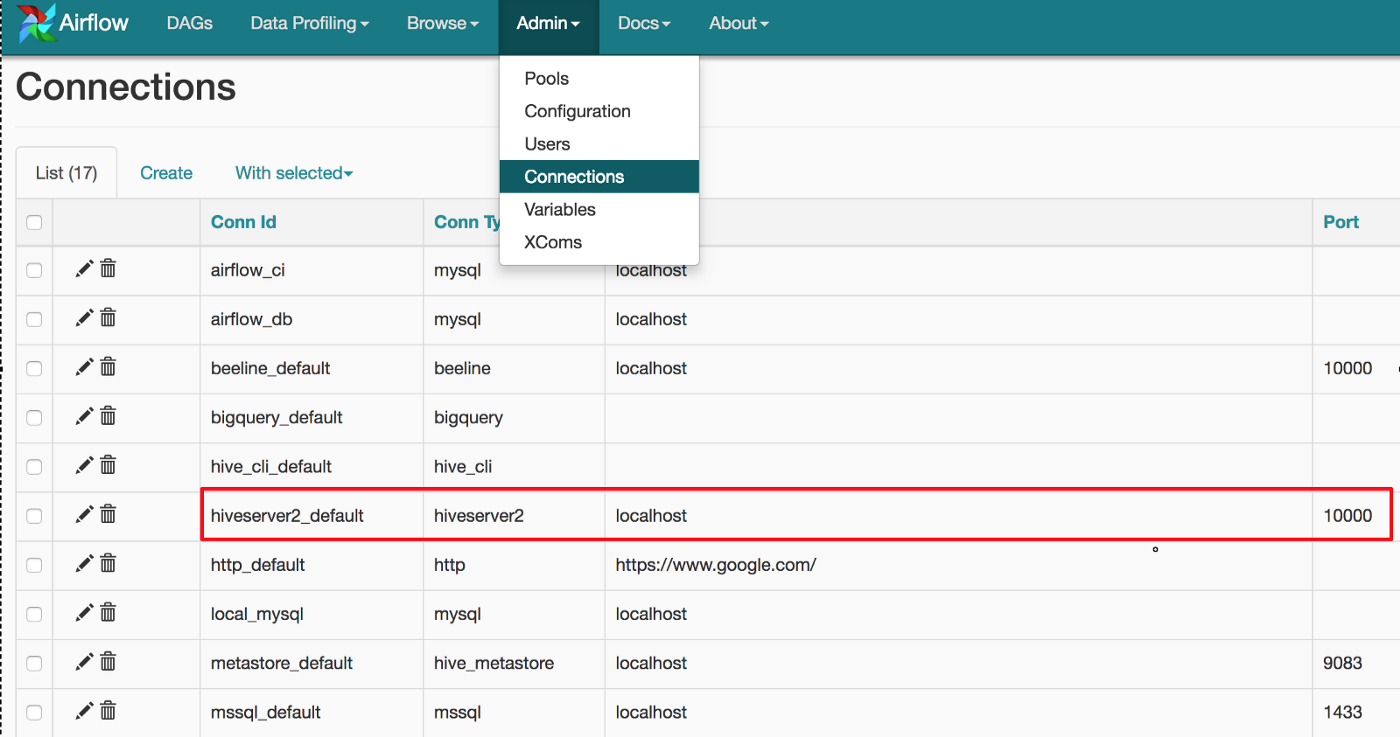
And that’s literally all you need to do to have an up and running Airflow server integrated within your data architecture. Now you can use its powerful capabilities to manage your data pipelines by conceiving your pipelines via Airflow’s DAGs system.
Then, let Spark do the hard work
Spark no longer needs an introduction, but in case you’re unfamiliar with the distributed data-processing framework that took the world by storm since it was open sourced in 2013,
As long as you’re running it on a cluster adequate to the size of your data, Spark offers ridiculously fast processing power. And through Spark SQL, it allows you to query your data as if you were using SQL or Hive-QL.
Now all you need to do is to use Spark within your Airflow tasks to process your data according to your business needs. I strongly recommend using the spypark sql and then using Airflow’s PythonOperator for your tasks; that way you get to execute your Spark jobs directly within the Airflow Python functions.
I also recommend relying on helper functions so that you don’t find yourself copy-pasting the same bits of code within different tasks.
Spark SQL offers equivalents to all of the operations that may be present within your queries, so the transition will definitely be seamless. Use PySpark to restructure your data according to your needs and then use its immense processing power to calculate multiple aggregations, then you could store its output on your database, through the Airflow hook.
Finally, enjoy the results through Zeppelin
Apache Zeppelin is another technology at the Apache Software Foundation that’s gaining massive popularity. Through its use of the notebook nit became the go-to data visualization tool in the Hadoop ecosystem.
Using Zeppelin allows you to visualize your data dynamically and in real-time, and through the form that ypu can create withina zepplin dashboard you could easily create dynamic scripts that use the forms’ input to run a specific set of operations on a dynamically specified data-set:
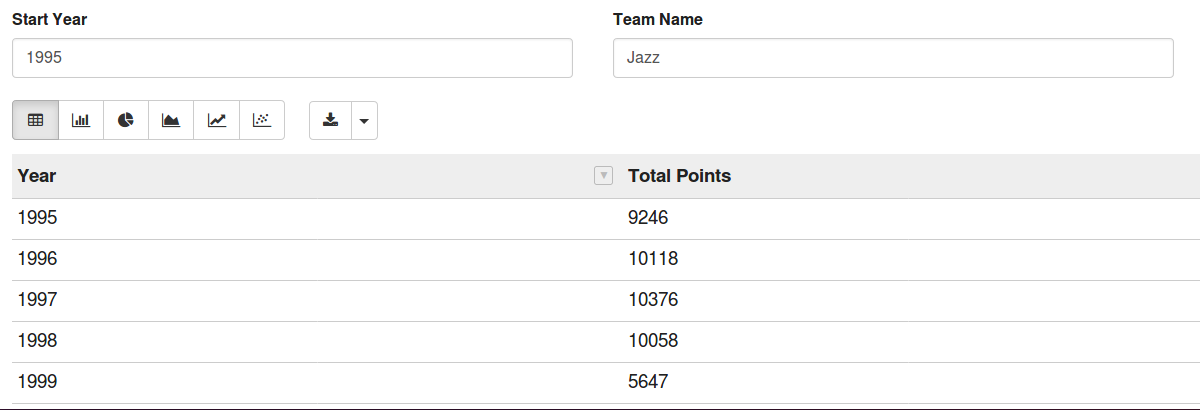
Thanks to these dynamic forms, a Zeppelin dashboard becomes an efficient tool to offer even users who have never written a line of code an instant and complete access to the company’s data.
Just like Airflow, Setting up with Zeppelin server is pretty straight forward. Then you just need to configure the Spark interpreter so that you can run PySpark scripts within Zeppelin notes on the data you already prepared via the Airflow-Spark pipeline.
Additionally, Zeppelin offers a huge number of interpreters allowing its notes to run multiple types of scripts (with the Spark interpreter being the most hyped).
After loading your data, visualizing it via multiple visualization types can be instantly done via the multiple paragraphs of the note:
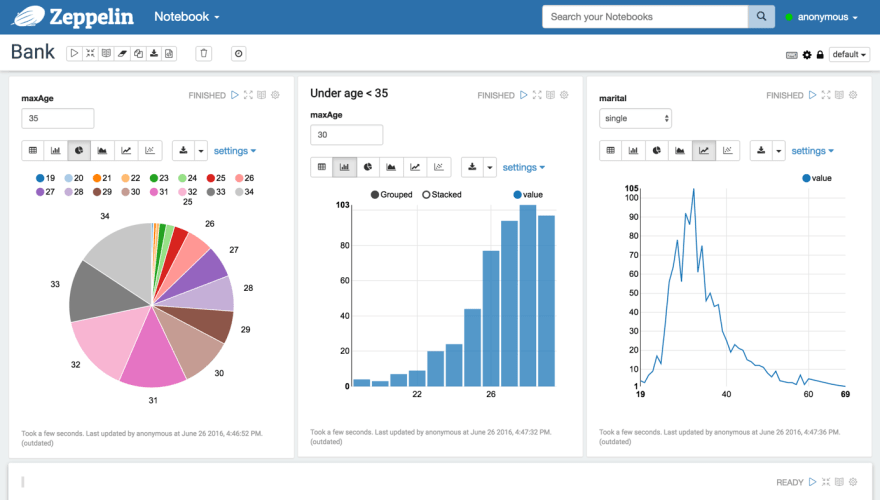
And with the release of Zeppelin 0.8.0 in 2018 you could now extend its capabilities (like adding custom visualizations) through Helium, its new plugin system.
And with the release of Zeppelin you could now extend its capabilities (like adding custom visualizations) through Helium, its new plugin system.
To integrate Zeppelin within the pipeline, all you need to do is to configure the Spark interpreter. And if you prefer to access the data calculated with Spark using your database instead, that’s also possible through the use of the appropriate Zeppelin interpreter.
That’s it!
That’s all you need to do to have an up and running Big Data pipeline that allows you to extract and visualize enormous amounts of information from your data.
Start by putting in place an Airflow server that organizes the pipeline, then rely on a Spark cluster to process and aggregate the data, and finally let Zeppelin guide you through the multiple stories your data can tell.
For any questions or if you need some help with one of these technologies, you could email me directly and I’ll get back to you as soon as possible.


0 Comments:
Post a Comment