





Most applications built with cognos tm1 training require some way to perform data ETL which is an acronym for extract, transform, and load. It is a process that involves extracting data from an outside source, transforming it into some form to fit an operational need, and then loading that newly formatted data into a target.
Intellipaat provides career-oriented cognos tm1 online training in order to help you move ahead in your career.

TM1 TurboIntergrator review
TM1 TurboIntegrator is the programming or scripting tool that allows you to automate data importation, metadata management, and many other tasks.
Within each process, there are six sections or tabs. They are as follows:
- Data Source
- Variables
- Maps
- Advanced
- Schedule
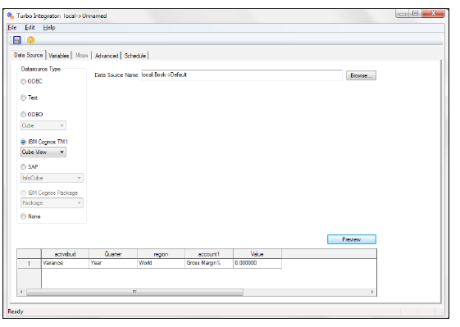
The Data Source tab
You use the Data Source tab to identify the source from which you want to import data to TM1. The fields and options available on the Data Source tab vary according to the Datasource Type that you select. Refer to the following screenshot:
TurboIntegrator local variables:
- DatasourceNameForServer: This variable lets us set the name of the data source to be used. This value can (and should) include a fully qualified path or other specific information that qualifies your data source.
- DatasourceNameForClient: It is similar to DatasourceNameForServer and in most cases will be the same value.
- DatasourceType: It defines the type or kind of data source to be used, for example, view or character delimited.
- DatasourceUsername: When connecting to an ODBC data source, this is the name used to connect to the data source.
- DatasourcePassword: It is used to set the password when connecting to an ODBC data source.
- DatasourceQuery: It is used to set the query or SQL string used when connecting to an ODBC data source.
- DatasourcecubeView: It is used to set the name of the cube view when reading from a TM1 cube view. This can be the name of an existing cube view or a view that the process itself defines.
- DatasourceDimensionsubset: It is used to set the name of the subset when reading from a TM1 subset. This can be the name of an existing subset or a subset that the process itself defines.
- DatasourceASCIIDelimiter: This can be used to set the ASCII character to be used as a field delimiter when DatasourceType is character delimited.
- DatasourceASCIIDecimalSeperator: This TI local variable sets the decimal separator to be used in any conversion from a string to a number or a number to a string.
- DatasourceASCIIThousandSeperator: This TI local variable sets the thousands separator to be used in any conversion from a string to a number or a number to a stringDatasourceASCIIQuoteCharacter: This TI local variable sets the ASCII character used to enclose the fields of the source file when DatasourceType is character delimited.
- DatasourceASCIIHeaderRecords: It specifies the number of records to be skipped before processing the data source.
Two additional variables to be aware of are:
- OnMinorErrorDoItemSkip: This TI local variable instructs TI to skip to the next record when a minor error is encountered while processing a record.
- MinorErrorLogMax: This TI local variable defines the number of minor errors that will be written to the TM1ProcessError.log file during process execution. If this variable is not defined in the process, the default number of minor errors written to the log file is 1000.
Using TurboIntegrator Variables
An information cube may be defined with two dimensions—application name and application measure. These two dimensions can be used to define a data point in a cube for specific applications to store and retrieve specific information, such as in the following example. Therefore, a TI process would read a file name to be loaded and the location of that file to be loaded:
datasourcePath =CellGetS(NameOfInformationCubeName,MeasureNameForCategoryMeasureNameForFilePathName ); dataFileName = CellGetS( InformationCubeName, MeasureNameForCategory, MeasureNameForFileName) ;
Additionally, the process may also read a location to write exceptions or errors that may occur during the processing:
exceptionFilePath = CellGetS( systemVariableCubeName, systemVariableCategory , systemVariableLogsFileName ) ;
Then, we can build our exception variable:
exceptionFileName = exceptionFilePath | 'my process name' |_ Exceptions.txt';
Finally, we use some of the previously mentioned process variables to actually set up our data source (and in this example we are using an ASCII text file as a data source):
# — set the datasource info for this process
DatasourceNameForServer = datasourcePath | dataFileName; DataSourceType = 'CHARACTERDELIMITED'; DatasourceASCIIDelimiter = ',';
Dynamic Definitions
Another advanced technique is to programmatically define a view in a TI process and then set that process’ data source to that view name. It is not that uncommon to define a View to zero-out cells in a cube to which the process will load incoming data, but it is little more interesting to define a view which will be read as input by the process itself.
Important TurboIntegrator functions
ExecuteProcess
It allows you to execute a TI process from within a TI process. The format is as follows:
ExecuteProcess(ProcessName, [ParamName1, ParamValue1, ParamName2, ParamValue2]);
The most important return values to know are as follows:
- ProcessExitNormal(): If your ExcuteProcess returns this, it indicates that the process executed normally.
- ProcessExitMinorError(): If your ExcuteProcess returns this, it indicates that the process executed successfully but encountered minor errors.
- ProcessExitByQuit(): If your ExcuteProcess returns this, it indicates that the process exited because of an explicit quit command.
- ProcessExitWithMessage(): If your ExcuteProcess returns this, it indicates that the process exited normally, with a message written to Tm1smsg.log.
- ProcessExitSeriousError(): If your ExcuteProcess returns this, it indicates that the process exited because of a serious error.
ItemSkip
The ItemSkip function can be used to skip a record or row of data.
If (record_is_invalid); ASCIIOutput (exceptionFile, recordId); ItemSkip; Endif;
ProcessBreak, ProcessError, and ProcessQuit
It is worth mentioning the following functions available in TI:
- ProcessBreak
- ProcessError
- ProcessQuit
These processes are important because they can be used to:
- Stop all processing and force control to the epilog
- Terminate a process immediately
- Terminate a process immediately with errors
View handling
ViewZeroOut
This function sets all data points (all cells) in a named view to zero. It is most often used after defining a very specific view.
PublishView
PublishView
This function is provided to publish a private view to the TM1 Server so that other TM1 Clients can see and use the view. This was not possible in early versions of TM1 unless you were a TM1 Administrator. The format of this function is:
PublishView(Cube, View, PublishPrivateSubsets, OverwriteExistingView);
The arguments (parameters) passed to the function are extremely important!
- PublishPrivateSubets
- OverWriteExistingView
CubeClearData
The importance of this function is simply that if you want to clear the entire cube, this function is extremely fast.
CellIsUpdateable
This is an important function. You can use this to avoid runtime TI generated errors but when using it before each cell insert the following lines:
If (CellsUpdateable(CubeName, DimName1, DimName2, DimName3=1); CellPutN(myValue, CubeName, DimName1, DimName2, DimName3); Else; ASCIIOuput(ExcpetionFile, RecordID, ErrorMsg); Endif;
SaveDataAll
This function saves all TM1 data from the server memory to disk and restarts the log file—IBM.
To avoid this problem, you can use the SaveDataAll function. However, it is important to use this function appropriately. This function used incorrectly can cause server locks and crashes.
SubsetGetSize
SubsetGetSize is a useful function that returns a count of the total elements that are in a given subset.
Security functions
- AddClient and DeleteClient: The AddClient function creates and the DeleteClient function deletes the clients on the TM1 Server. These functions must be used in the metadata section of a TI process.
- AddGroup and DeleteGroup: The AddGroup function creates and the DeleteGroup function deletes the groups on the TM1 Server. These functions must be used in the metadata section of the TI process.
- AssignClientToGroup and RemoveClientFromGroup: The AssignClientToGroup function will assign and the RemoveClientFromGroup will remove an existing client from an existing group.
- ElementSecurityGet and ElementSecurityPut: The ElementSecurityGet function is used to assign and the ElementSecurityPut function is used to retrieve a security level for an existing group for a specific dimension element. The security levels can be None, Read, Write, Reserve, Lock, and Admin.
- SecurityRefresh: The SecurityRefresh function reads all of the currently set up TM1 security information and applies that information to all of the TM1 objects on the TM1 Server. Be advised, depending on the complexity of the TM1 model and the security that has been set up, this function may take a very long time to execute and during this time all users are locked.
Rules and feeders Management functions
The following three functions can be used to maintain cube rules and feeders. They are important to be familiar with:
- CubeProcessFeeders
- DeleteAllPersistantFeeders
- ForceSkipCheck
- RuleLoadFromFile
CubeProcessFeeders
This function becomes important if you are using conditional feeders. Whenever you edit and save a cube rule file, feeders get automatically reprocessed by TM1. You can use this function to ensure that all of the conditional feeders are reprocessed. Keep in mind that all of the feeders for the cube will be reprocessed:
CubeProcessFeeders(CubeName);
DeleteAllPersistentFeeders
To improve performance you can define feeders as persistent. TM1 then saves these feeders into a .feeder file. These feeder files will persist (remain) until they are physically removed. You can use the DeleteAllPersistentFeeders function to clean up these files.
ForceSkipCheck
This function can be placed in the prolog section of a TI process to force TM1 to perform as if the cube to which the process is querying has SkipCheck in its rules— meaning it will only see cells with values rather than every single cell.
RuleLoadFromFile
This function will load a cube’s rule file from a properly formatted text file. If you leave the text file argument empty, TI looks for a source file with the same name as the cube (but with a .rux extension) in the server’s data directory.
RuleLoadFromFile(Cube, TextFileName);
SubsetCreateByMDX
This function creates a subset based upon a properly formatted MDX expression.
MDX is a powerful way to create complicated lists. However, TM1 only supports a small number of MDX functions (not the complete MDX list). The format of this function is as follows:
SubsetCreatebyMDX(SubName, MDX_Expression);
ExecuteCommand
This is a function that you can use to execute a command line. The great thing about this is that you can do all sorts of clever things from within a TI process. The most useful is to execute an external script or MS Windows command file. The format of this function is as follows:
ExecuteCommand(CommandLine, Wait);
CommandLine is the command line you want to execute and the Wait parameter will be set to either 1 or 0 to indicate if the process should wait for the command to complete before proceeding.
Order of operations within a TurboIntegrator process
- When you run a TI process, the procedures are executed in the following sequence (basically left to right as they are displayed)
- Prolog
- Metadata
- Data
- Epilog
- Prolog is executed one time only.
- If the data source for the process is None, Metadata and Data are disabled and do not execute.
- If the data source for the process is None, Epilog executes one time immediately after Prolog finishes processing.
- If the data source for the process is not None, Metadata and Data will execute for each record in the data source.
- Code to build or modify a TM1 dimension resides in the Metadata
- The Metadata tab is used to build TM1 subsets.
- All lines of code in the metadata procedure are sequentially executed for each record in the data source.
- All lines of code in the data procedure are sequentially executed for each record in the data source.
- Because the data procedure is executed for each row or record in the data source, an error is generated in the procedure for multiple times.
- The data procedure is the procedure used to write/edit code used to load data into a cube.The data source is closed after the data procedure is completed.
- The epilog procedure is always the last procedure to be executed.
- Not all TM1 functions will work as expected in every procedure.
- Aliases in TurboIntegrator functions
Let us suppose that a company does forecasting on a monthly basis. Each month a new version of the working forecast is created. For example, in January the forecast consists of 12 months of forecasted sales (January through December). In February, the working forecast consists of one month (January) of actual sales data and 11 months of forecasted sales (February through December). In March, the working forecast consists of two months (January and February) of actual sales and 10 months of forecasted sales—and so on. In this example, you can define an alias attribute on the version dimension and use it to refer to whatever version of the forecast is currently running (or is the working version).
Then, TI processes can refer to a version as the working forecast (the alias) and always connect to the correct version.
CubeSetLogChanges
In TI, you can turn on (or turn off) cube logging using the function CubeSetLogChanges. Be very careful to understand when and why to turn on (or off) cube logging. If data changes are to be made to a cube with your TI process and you need to ensure that you can recover those changes in the event of a server crash, you need to assure that logging is on. If it is not important to recover changes made by the TI process, set cube logging off to improve performance.
Revisiting variable types.
In the Contents column of the TurboIntegrator Variables tab you indicate what you want to do with the data in that variable. The options are:
- Ignore: If you have a variable set to Ignore, TI will not be able to see or use it at all and if you refer to it in any part of your code, you will get an error message when you try to save the process.
- Element, Consolidation, Data, or Attribute: These are only used when you are having TI to generate the code via the GUI. This tells TI that the contents of this variable should be one of the following:
- An element name or consolidation name (which TI can use to update the relevant dimension)
- A piece of data, which TI can write into a cube
- An attribute, which is also used to update a dimension,To more visit:cognos tm1 training


0 Comments:
Post a Comment