





parameter — — — — — — — in document
lsi — — — — — — — — — — — -present
focus keyword — — — — — — — — — -HDFS
kw density — — — — — — -1k-10k
fkw density — — — — — — — — — — 1.5
flesch — — — — — — — — — — -53
plagiarsim — — — — — — - unique
lsi — — — — — — — — — — — -present
focus keyword — — — — — — — — — -HDFS
kw density — — — — — — -1k-10k
fkw density — — — — — — — — — — 1.5
flesch — — — — — — — — — — -53
plagiarsim — — — — — — - unique
Hadoop can store and process any file data: large or small, whether it is plain text files or binary files such as images, even multiple copies of a specific data format over various periods of time. You can change the way your Hadoop data is processed and analysed at any time.
This article addresses essential HDFS cluster configuration files for Hadoop, and offers examples of the same. Before getting to know Hadoop cluster configuration it is important to know core configuration files and their properties.
To learn complete Big data hadoop tutorials visit:big data hadoop course.
The.xml and hdfs-site.xml core:
The file core-site.xml tells daemon Hadoop where NameNode is running in the cluster. It includes the Hadoop Core configuration settings, such as I / O settings specific to both HDFS and MapReduce.
The hdfs-site.xml file includes HDFS daemon configuration settings like NameNode, Secondary NameNode, and DataNodes, respectively. Here we can configure hdfs-site.xml to define the default replication block and HDFS search for permission. Additionally, you can determine the actual number of replications when making the file. The default is used in case replication is not defined in time to build. Now that you have learned about .xml and hdfs-site.xml core files. Let us learn about descriptions of these core files.
The file core-site.xml tells daemon Hadoop where NameNode is running in the cluster. It includes the Hadoop Core configuration settings, such as I / O settings specific to both HDFS and MapReduce.
The hdfs-site.xml file includes HDFS daemon configuration settings like NameNode, Secondary NameNode, and DataNodes, respectively. Here we can configure hdfs-site.xml to define the default replication block and HDFS search for permission. Additionally, you can determine the actual number of replications when making the file. The default is used in case replication is not defined in time to build. Now that you have learned about .xml and hdfs-site.xml core files. Let us learn about descriptions of these core files.
Defining descriptions of HDFS in hdfs-site.xml configuration file:
● dfs.data.dir
It contains list of directories where data node stores blocks.
● fs.checkpoint.dr
It contains list of directories where secondary name node stores directories.
● dfs.data.dir
It contains list of directories where data node stores blocks.
● fs.checkpoint.dr
It contains list of directories where secondary name node stores directories.
● Mapred place.xml:
The mapred-site.xml file contains MapReduce daemon configuration settings; job tracker, and task tracker.
Environment Per-Process runtime:
hadoop-env.sh ==— → jvm
This file provides a way for each of the servers to have client parameters. Hadoop-env.sh is compiled from all the core Hadoop scripts provided in the installation's 'conf/' directory.
Below are some examples of variables for the system which can be specified.
● HADOOP DATANODE HEAPSIZE = "128′′
● HADOOP TASKTRACKER HEAPSIZE='512
The reporting is managed by the file 'hadoop-metrics.properties,' and the default condition is set as to not report.
Core Properties:
● Fs.default.
● With Hadoop.tmp.dir
● Mapred.emplob.tracker
Urls Web UI:
NodeName: http:/localhost:50070 / dfshealth.jsp
● Jobs: http:/localhost:50030 / jobtracker.jsp
● TaskTrackerstatus:~localhost:50060 / tasktracker.jsp
● Test DataBlockScanner: ht:/localhost:50075 / blockScannerReport
The Hadoop-env.sh, core-ite.xml, hdfs-site.xml, mapred-site.xml, Masters and Slaves can all be found under the Hadoop installation directory's 'conf.' Let us see about Hadoop cluster configuration files.
Hadoop cluster configuration files
Below are some examples of variables for the system which can be specified.
● HADOOP DATANODE HEAPSIZE = "128′′
● HADOOP TASKTRACKER HEAPSIZE='512
The reporting is managed by the file 'hadoop-metrics.properties,' and the default condition is set as to not report.
Core Properties:
● Fs.default.
● With Hadoop.tmp.dir
● Mapred.emplob.tracker
Urls Web UI:
NodeName: http:/localhost:50070 / dfshealth.jsp
● Jobs: http:/localhost:50030 / jobtracker.jsp
● TaskTrackerstatus:~localhost:50060 / tasktracker.jsp
● Test DataBlockScanner: ht:/localhost:50075 / blockScannerReport
The Hadoop-env.sh, core-ite.xml, hdfs-site.xml, mapred-site.xml, Masters and Slaves can all be found under the Hadoop installation directory's 'conf.' Let us see about Hadoop cluster configuration files.
Hadoop cluster configuration files
Let's look at the files one by one, and their use!
Hadoop- Env.sh
Hadoop- Env.sh
This file specifies environment variables affecting the JDK that Hadoop Daemon (bin or hadoop) uses.
As Hadoop system is written in Java and uses the Java Runtime environment, $JAVA HOME in hadoop- env.sh is one of the essential environment variables for Hadoop daemon. This variable guides the daemon Hadoop into the system's Java path. This file is also used to set other execution environment for Hadoop daemon, such as heap size
(HADOOP HEAP), hadoop home (HADOOP HOME), log file position (HADOOP LOG DIR), etc.
Note: We have configured only the necessary parameters to start a cluster for simplicity in understanding the cluster setup.
The following three files show the essential configuration files for a Hadoop cluster's runtime environment settings.
The core-site .sh
This file keeps Hadoop daemon aware where NameNode is running in the cluster. It includes the Hadoop Core configuration settings, such as I / O settings specific to both HDFS and MapReduce.
Code node, Hadoop daemon, setup settings, Hadoop Core
Where the hostname and port on which NameNode daemon runs and listens. It also informs the Name Node which IP and port it should be binding on. The normal port is 8020, and you can also indicate IP address instead of hostname.
The hdfs-site.sh
The hdfs site.sh file contains configuration settings for the HDFS daemon. They are as follows
● Main Node,
● Secondary Name Node, and
● Data Nodes.
Hdfs-site.xml can also be configured to define the default block replication and permission search on HDFS. Additionally, you can determine the actual number of replications when making the file. The default is used in case replication is not defined in time to build.
The value "real" for property 'dfs.permissions' allows to check permission in HDFS and the value "false"
cuts off checking permission. Switching from one parameter to another doesn't alter the file or directory mode, user, or party.
HDFS daemons, naming nodes, secondary nodes and data nodes
Site-mapred.sh
As Hadoop system is written in Java and uses the Java Runtime environment, $JAVA HOME in hadoop- env.sh is one of the essential environment variables for Hadoop daemon. This variable guides the daemon Hadoop into the system's Java path. This file is also used to set other execution environment for Hadoop daemon, such as heap size
(HADOOP HEAP), hadoop home (HADOOP HOME), log file position (HADOOP LOG DIR), etc.
Note: We have configured only the necessary parameters to start a cluster for simplicity in understanding the cluster setup.
The following three files show the essential configuration files for a Hadoop cluster's runtime environment settings.
The core-site .sh
This file keeps Hadoop daemon aware where NameNode is running in the cluster. It includes the Hadoop Core configuration settings, such as I / O settings specific to both HDFS and MapReduce.
Code node, Hadoop daemon, setup settings, Hadoop Core
Where the hostname and port on which NameNode daemon runs and listens. It also informs the Name Node which IP and port it should be binding on. The normal port is 8020, and you can also indicate IP address instead of hostname.
The hdfs-site.sh
The hdfs site.sh file contains configuration settings for the HDFS daemon. They are as follows
● Main Node,
● Secondary Name Node, and
● Data Nodes.
Hdfs-site.xml can also be configured to define the default block replication and permission search on HDFS. Additionally, you can determine the actual number of replications when making the file. The default is used in case replication is not defined in time to build.
The value "real" for property 'dfs.permissions' allows to check permission in HDFS and the value "false"
cuts off checking permission. Switching from one parameter to another doesn't alter the file or directory mode, user, or party.
HDFS daemons, naming nodes, secondary nodes and data nodes
Site-mapred.sh
This file includes MapReduce daemon configuration settings; work tracker and task-tracker. The mapred.work.tracker parameter is a hostname or IP address. Then the port pair on which the Job Tracker listens for RPC communication. This parameter defines where the Job Tracker is located for Task .
Trackers and MapReduce clients.
● MapReduce
● Daemons
● Job manager and
● Job-tracker
All four files listed above can be replicated to all Data Nodes and Secondary Namenode. These files can then be configured for any configuration unique to a node, e.g. in the case of a different JAVA HOME on one of the Datanodes.
In the Hadoop cluster, the following two files 'masters' and 'slaves' decide the master and slave Nodes.
Masters & Slaves:
Slaves contain a list of hosts, one per line, required to host the servers DataNode and TaskTracker. The Masters provide a list of hosts that are needed to host secondary NameNode servers, one per line. The
Masters file tells Hadoop daemon about the location of the Secondary NameNode. The Main domain file'Masters' includes a domain hostname, Secondary Name Node.
This file informs to hadoop daemon about the location of the Secondary Namenode. The Master server 'masters' file includes servers with a hostname Secondary Name Node.The file on Slave Nodes with
'masters' is blank.The Master node 'slaves' file contains a list of hosts to host Data Node and Task Tracker servers, one per line.The file 'slaves' on Slave Server includes the slave node's IP address. Note that the Slave node 'slaves' file only contains its own IP address and not any other cluster data nodes.
Hadoop Cluster on Facebook:
Facebook uses Hadoop as a platform for reporting, analytics , and machine learning to store copies of internal log and dimensional data sources. Facebook currently has two large clusters: a cluster of 1100
machines with 800 cores, and approximately 12 PB of raw capacity. Another one is a cluster of 300 computers with 2,400 cores and raw capacity of about 3 PB. — commodity node has 8 cores, and storage of 12 TB.
Facebook uses streaming and Java API a lot and has used Hive to create a platform for data warehousing at a higher level. They created an application for FUSE over HDFS, too.
● MapReduce
● Daemons
● Job manager and
● Job-tracker
All four files listed above can be replicated to all Data Nodes and Secondary Namenode. These files can then be configured for any configuration unique to a node, e.g. in the case of a different JAVA HOME on one of the Datanodes.
In the Hadoop cluster, the following two files 'masters' and 'slaves' decide the master and slave Nodes.
Masters & Slaves:
Slaves contain a list of hosts, one per line, required to host the servers DataNode and TaskTracker. The Masters provide a list of hosts that are needed to host secondary NameNode servers, one per line. The
Masters file tells Hadoop daemon about the location of the Secondary NameNode. The Main domain file'Masters' includes a domain hostname, Secondary Name Node.
This file informs to hadoop daemon about the location of the Secondary Namenode. The Master server 'masters' file includes servers with a hostname Secondary Name Node.The file on Slave Nodes with
'masters' is blank.The Master node 'slaves' file contains a list of hosts to host Data Node and Task Tracker servers, one per line.The file 'slaves' on Slave Server includes the slave node's IP address. Note that the Slave node 'slaves' file only contains its own IP address and not any other cluster data nodes.
Hadoop Cluster on Facebook:
Facebook uses Hadoop as a platform for reporting, analytics , and machine learning to store copies of internal log and dimensional data sources. Facebook currently has two large clusters: a cluster of 1100
machines with 800 cores, and approximately 12 PB of raw capacity. Another one is a cluster of 300 computers with 2,400 cores and raw capacity of about 3 PB. — commodity node has 8 cores, and storage of 12 TB.
Facebook uses streaming and Java API a lot and has used Hive to create a platform for data warehousing at a higher level. They created an application for FUSE over HDFS, too.
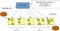

The above picture clearly illustrates how each node is configured. NameNode has a high ram capacity and should have a lot of RAM and has little hard disk ram. For a secondary NameNode the memory requirement isn't as high as the main NameNode. — DataNode requires 16 GB of memory and is high on
the hard disk, as the data will be stored. Often, they have several drives.
Conclusion:
I hope you reach a conclusion about Hadoop HDFS cluster configuration files. You can learn more through big data and hadoop training.
the hard disk, as the data will be stored. Often, they have several drives.
Conclusion:
I hope you reach a conclusion about Hadoop HDFS cluster configuration files. You can learn more through big data and hadoop training.


0 Comments:
Post a Comment